Please fix this network problem
Hello. If you are reading this, I got very lucky by promoting an ad on Google Ads. I hope you are a Meta network engineer; even if you are not, please try to relay this information internally.
Meta has a problem in its clusters in Boca Raton, Miami; this is affecting the MNA content delivery network and direct content consumption. This has a regional impact in Latin America, since so far most non-cacheable content is consumed from the clusters in Florida.

Evidence:
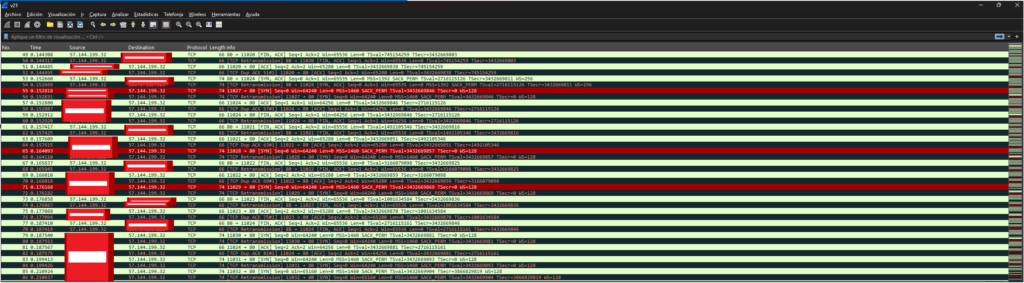
The impact is traceable via ICMP, but also reproducible via TCP and difficult to measure via UDP. This is why monitoring tools are misleading: there is no “slowness” resulting from interface saturation; instead, there is data corruption where packets are discarded at the interface level. Therefore, if network performance is measured using those same data points, it won’t work and you won’t see any alerts.
Blah blah blah, I don’t want this to be mistaken for a false alarm, so I’ll get straight to the point:
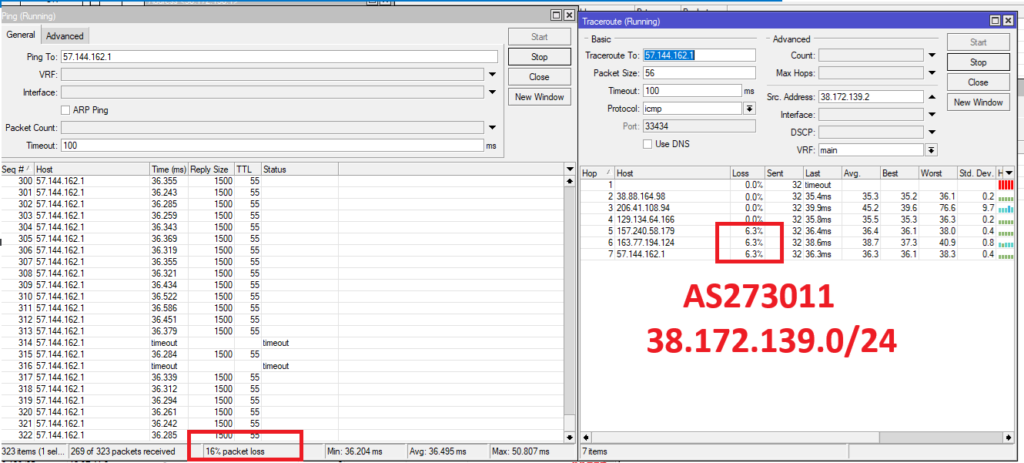
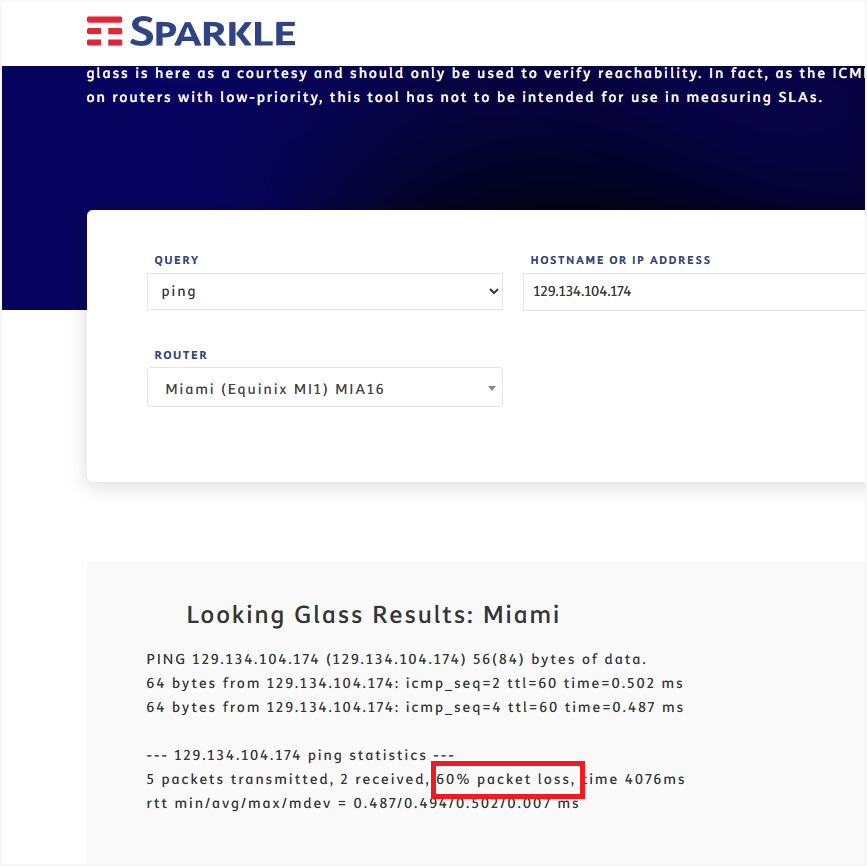
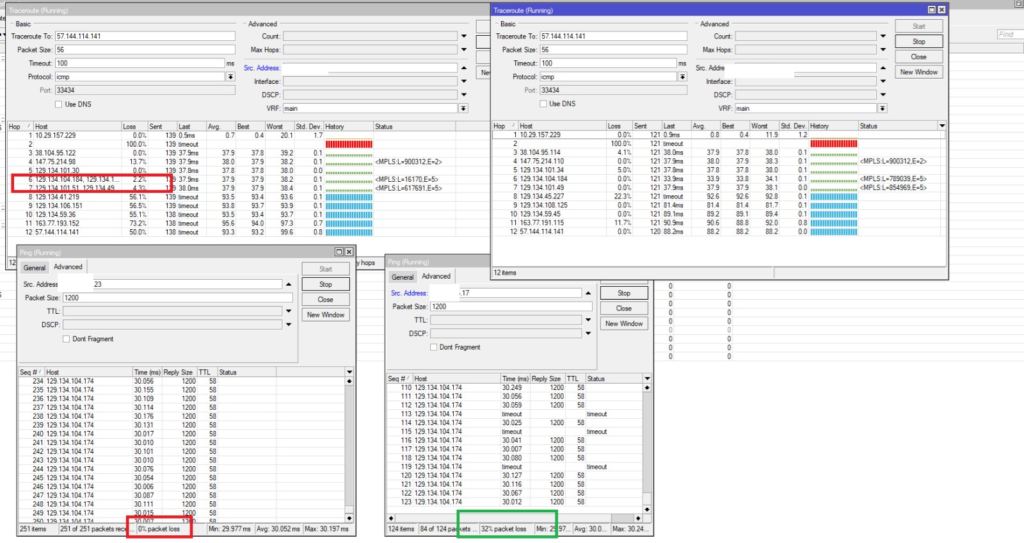
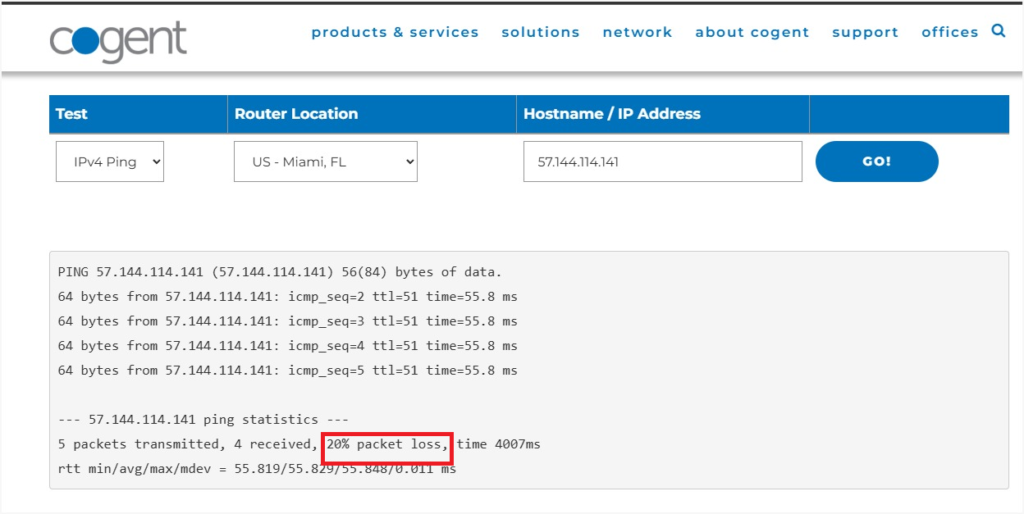
There is packet loss and probably flapping on a BGP instance, OSPF, or some IGP within Meta’s network. I believe it is between 129.134.101.34, 129.134.104.84, and 129.134.101.51. It is possible that it’s a faulty interface in a bundle or some hardware issue that a “show interface status” doesn’t reveal, which is why I’ve failed to report this problem through your NOC.
What to do with this?
I am a network engineer advising small companies, but I have about 5 clients in different countries, so I have very good visibility into these problems. I can assure you that this is an endemic problem that translates into a terrible experience for Meta services. This failure has been present for about 7 months, and it has been 5 months since I first reported it. This has happened on a previous occasion and I faced the same reporting difficulties, something like:
Me: Hi, I see a problem here. Meta: Hi, how about sending me some irrelevant evidence? Me: I’m sending it because I know it’s protocol, but I’m trying to send the correct information too. Meta: We don’t see anything, bro. Me: OK, I understand you don’t see anything, but look, there are a lot of affected networks (sending evidence). Meta: Haha, this guy—we’re not going to fix anything we don’t see.
The same thing happened in 2023. The ticket was resolved after 6 months when I used a “fake” ticket to get someone from Meta technical support to check the failing interface, and it was fixed 1 day later. So I know firsthand that your monitoring systems simply don’t work for these types of problems.
How can Meta replicate the failure?
1: Look for random MNA cluster IPs from your clients. 2: Ping from 157.240.14.15 with a payload larger than 500 bytes (a packet is more likely to get corrupted on a faulty interface if the payload increases). 3: Ping many servers from point 1.
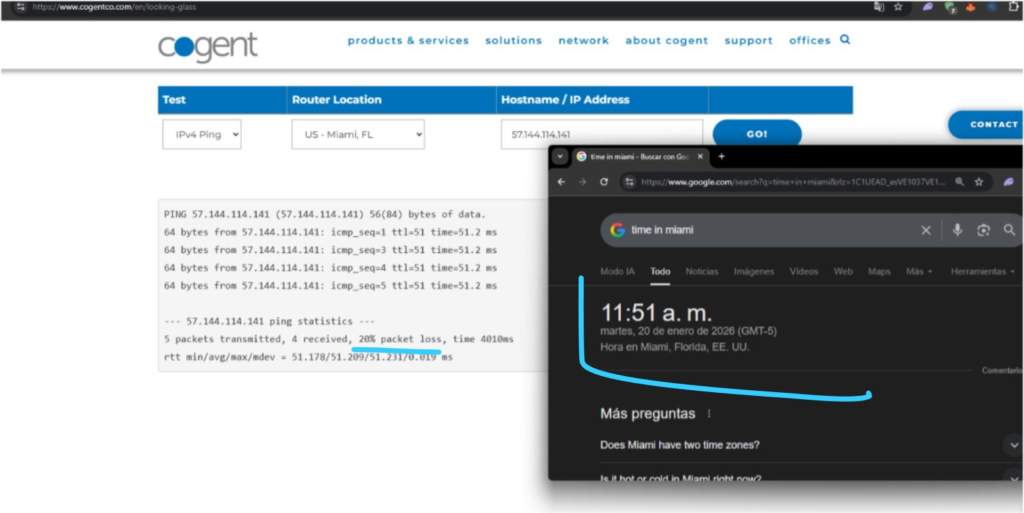
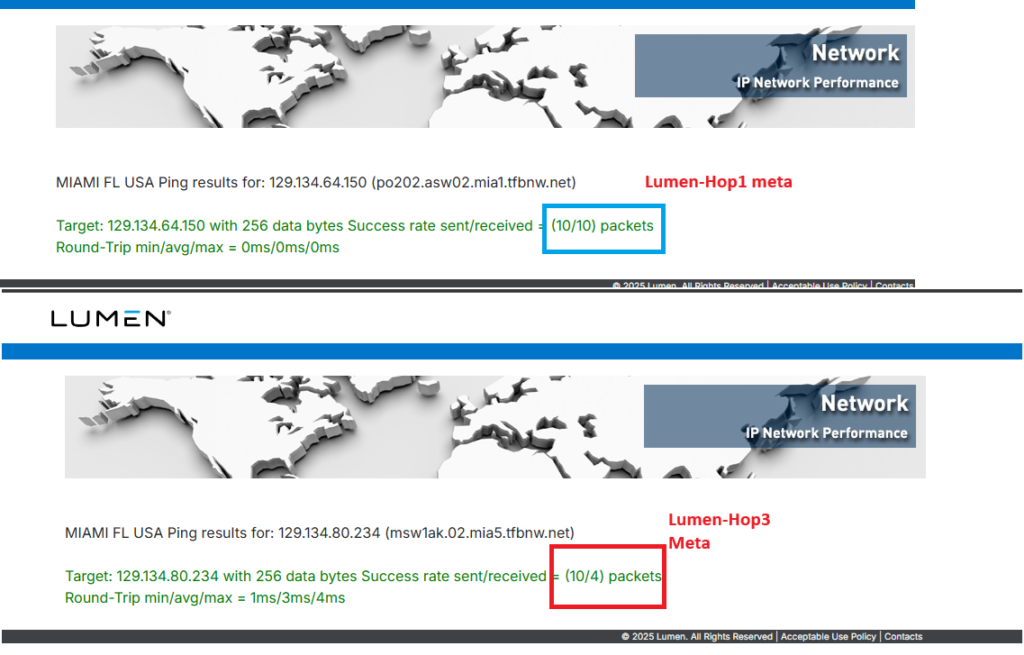
You will see that once you find the affected upstream or downstream route combination, you will have 10-60% packet loss to the destination host.
How to fix it? Isolate the port or discard faulty hardware.
Why didn’t we see it before?
Simply put, your monitoring tools and troubleshooting protocols don’t work for these problems. The protocol is to attach a HAR file that bases its performance on window scaling and TCP RTT; if both are good, even with data loss, there’s “no problem.” Especially because that HAR file is extracted using QUIC, and QUIC is particularly good at mitigating slowness caused by data loss (since packets are retransmitted without the TCP penalty). You know what uses TCP? WhatsApp Statuses, and those are slow.
Can an MTR show where the problem is?
Generally not, this is because:
In any network route, there is a certain number of hops; for example, suppose there are 5 hops between host A and host B. To perform a traceroute, packets are sent with increasing TTL values (1, 2, 3, etc.). Each time a packet expires before reaching its destination, the transit hop reports a “TTL Time Exceeded” message, which is how the route is mapped. The problem is that these are basically point-to-point probes; it’s like pinging each hop individually. And when there’s a problem on an affected interface in an ECMP or bundle, those P2P connections won’t necessarily take the affected path. So they are unreliable; generally, you will see that the losses are produced by the final host even though the fault is in the middle.
Please, if you don’t find anything, contact me. I will help you by providing an asymmetrical view of the problem. Help me help you and, in turn, help others. synthesis4x@gmail.com